Réponses des exercices numpy¶
Création de tableaux¶
Exercices : créer les tableaux suivants de la manière la plus simple possible (pas élément par élement)
[[ 1. 1. 1. 1.]
[ 1. 1. 1. 1.]
[ 1. 1. 1. 2.]
[ 1. 6. 1. 1.]]
[[0 0 0 0 0]
[2 0 0 0 0]
[0 3 0 0 0]
[0 0 4 0 0]
[0 0 0 5 0]
[0 0 0 0 6]]
Voilà les réponses !
Réponses
>>> a = np.ones((4,4))
>>> a[3,1] = 6
>>> a[2,3] = 2
>>> a
array([[ 1., 1., 1., 1.],
[ 1., 1., 1., 1.],
[ 1., 1., 1., 2.],
[ 1., 6., 1., 1.]])
>>> b = np.diag(np.arange(1,7))
>>> b = b[:,1:]
>>> b
array([[0, 0, 0, 0, 0],
[2, 0, 0, 0, 0],
[0, 3, 0, 0, 0],
[0, 0, 4, 0, 0],
[0, 0, 0, 5, 0],
[0, 0, 0, 0, 6]])
Statistiques du pourcentage de femmes dans la recherche française¶
- Récupérer les fichiers organismes.txt et pourcentage_femmes.txt (clé USB).
- Créer un tableau data en ouvrant le fichier pourcentage_femmes.txt avec np.loadtxt. Quelle est la taille de ce tableau ?
>>> data = np.loadtxt('pourcentage_femmes.txt')
>>> data.shape
(21, 6)
- Les colonnes correspondent aux années 2006 à 2001. Créer un tableau annees (sans accent !) contenant les entiers correspondant à ces années.
>>> annees = np.arange(2006, 2000, -1)
>>> annees
array([2006, 2005, 2004, 2003, 2002, 2001])
- Les différentes lignes correspondent à différents organismes de recherche dont les noms sont stockés dans le fichier organismes.txt. Créer un tableau organisms en ouvrant ce fichier. Attention : comme np.loadtxt crée par défaut des tableaux de flottants, il faut lui préciser qu’on veut créer un tableau de strings : organisms = np.loadtxt('organismes.txt', dtype=str)
>>> organisms = np.loadtxt('organismes.txt', dtype=str)
>>> organisms
array(['ADEME', 'BRGM', 'CEA', 'CEMAGREF', 'CIRAD', 'CNES', 'CNRS', 'CSTB',
'IFREMER', 'INED', 'INERIS', 'INRA', 'INRETS', 'INRIA', 'INSERM',
'IRD', 'IRSN', 'LCPC', 'ONERA', 'Pasteur', 'Universites'],
dtype='|S11')
- Vérifier que le nombre de lignes de data est égal au nombre d’organismes.
>>> data.shape[0] == organisms.shape[0]
True
- Quel est le pourcentage maximal de femmes dans tous les organismes, toutes années confondues ?
>>> data.max() # max sur tout le tableau
56.299999999999997
- Créer un tableau contenant la moyenne temporelle du pourcentage de femmes pour chaque organisme (i.e., faire la moyenne de data suivant l’axe No 1).
>>> mn = data.mean(axis=1)
>>> mn
array([ 37.8 , 23.16666667, 25.15 , 24.51666667,
24.38333333, 25.46666667, 30.88333333, 23.36666667,
25.08333333, 52.53333333, 29.33333333, 37.58333333,
31.86666667, 18.21666667, 50.16666667, 23.23333333,
33.45 , 15.18333333, 14.35 , 49.86666667, 33.41666667])
- Quel organisme avait le pourcentage de femmes le plus élevé en 2004 ? (Indice np.argmax).
>>> np.nonzero(annees==2004)
(array([2]),)
>>> np.argmax(data[:,2])
9
>>> organisms[9]
'INED'
- Un peu plus compliqué : créez un tableau contenant l’organisme avec le pourcentage de femmes le plus élévé de chaque année.
>>> indices = np.argmax(data, axis=0)
>>> indices
array([ 9, 9, 9, 9, 9, 19])
>>> organisms[indices]
array(['INED', 'INED', 'INED', 'INED', 'INED', 'Pasteur'],
dtype='|S11')
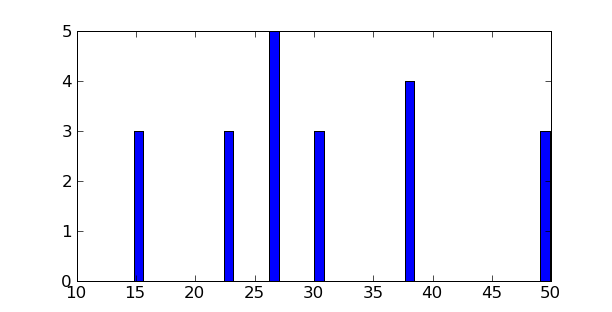
- Représenter un histogramme du pourcentage de femmes dans les différents organismes en 2006 (indice : np.histogram, puis bar ou plot de matplotlib pour la visualisation).
>>> np.nonzero(annees==2006)
(array([0]),)
>>> hi = np.histogram(data[:,0])
In [88]: bar(hi[1][:-1], hi[0])
Suite de l’exercice
- 1. Créer un tableau sup30 de même taille que data valant 1 si la valeur de data est supérieure à 30%, et 0 sinon.
>>> sup30 = data>30
- Un peu plus compliqué : créez un tableau contenant l’organisme avec le pourcentage de femmes le plus élévé de chaque année.
>>> indices = np.argmax(data, axis=0)
>>> indices
array([ 9, 9, 9, 9, 9, 19])
>>> organisms[indices]
array(['INED', 'INED', 'INED', 'INED', 'INED', 'Pasteur'],
dtype='|S11')